Cite this as: Katsianis, M., Bruseker, G., Nenova, D., Marlet, O., Hivert, F., Hiebel, G., Ore, C.-E., Derudas, P., Opitz , R.and Uleberg, E. 2023 Semantic Modelling of Archaeological Excavation Data. A review of the current state of the art and a roadmap of activities, Internet Archaeology 64. https://doi.org/10.11141/ia.64.12
Let's begin with a question. If the archaeological community succeeded in connecting its excavation data at a granular level following FAIR principles (Wilkinson 2016), with links between individual entities (fields in tables or items in a triple) so that ceramics, lithics, phytoliths, and silty clay stratigraphic units could be aggregated, quantified, and interrogated across a region, what uses would be made of this information resource? The Tiber Valley Restudy (Patterson et al. 2020), Archaedyn (Ferdière 2023), and the English Landscapes and Identities Project (Cooper and Green 2017) provide examples of research applications exploiting the informational capacity of datasets aggregated at the level of distinct archaeological features or single objects. Aggregated data such as these have been used to revise date ranges assigned to ceramics, to assess shifts in regional settlement or land cover patterns, and to interrogate trade networks and links in material culture. These examples indicate two broad research application areas: 1) creating robust estimates for key items of information (e.g. the spatiotemporal distribution of a type of ceramic dish), which can then be used to refine or challenge existing interpretations (e.g. revise chronological time spans) or assess new material (e.g. the dates of newly excavated features), and 2) modelling patterns and trends in data across a region or network in response to needs identified by domain specialists or individual research interests (e.g. the orientation of burials in the European Neolithic or the use of water-sieving in excavation fieldwork).
For researchers, accountability to data and data exploration can also provide mechanisms for questioning and re-evaluating established narratives and assumptions about the character of the archaeological record. In development-led archaeology these data may be used as inputs to predictive models for assessing not simply the likely presence of a site, but the probable range of preservation levels. In heritage management they may contextualise the significance of individual features or landscape areas, while in broader land use planning, they can be used to better inform land use change decisions by providing information which allows a planner to understand whether a feature or find is common, uncommon, common but in an uncommon context, or part of a meaningful wider pattern.
Generalising from these examples, the projected usefulness of aggregated archaeological datasets depends on the premises that: 1) there are benefits to tying heritage management decisions or narratives constructed about the past closely and traceably with archaeological observations and data, and 2) these benefits outweigh the effort required to produce knowledge and take decisions with a high degree of accountability to the underpinning data.
The first premise in particular is, admittedly, debated, with some advocating for greater accountability and some seeing this model of knowledge production as a poor fit for the realities of archaeological interpretation and decision making. Various obstacles to holding interpretation accountable to data have been raised, from a lack of resources for migrating existing data into such a system, to the impossibility of getting agreement on the meanings of archaeological categories, but most salient is the fact that most interpreters and decision makers simply don't use detailed data when making interpretations and decisions - not because of a lack of detailed data and tools to use them, but because detailed data are not part of this stage of the interpretive process. Furthermore, concerns have been raised about the kinds of knowledge left behind due to the 'emerging supremacy of structured digital data in archaeology' (Hacıgüzeller et al. 2021).
Making it easier to aggregate data and produce FAIR data is key to addressing critiques of the second premise, which emphasises that the effort required currently outweighs the benefits. In this article we focus on recent work within the ARIADNEplus community, assessing the technical and data management problems that hinder integration and add weight to the 'makes accountability to data too difficult' side of the costs-benefits balance sheet. We examine whether these issues, which encompass semantic, data modelling and ontological problems, remain an insurmountable obstacle, or if the real challenges now lie in successfully making the case for the benefits in various contexts to drive uptake.
To make a high-level assessment of this technology and data infrastructure landscape, data models provided by the CIDOC CRM and its extensions, as well as the AO-Cat model, were reviewed to check their coverage of the data elements commonly found in excavation data. Data cleaning, modelling, transformation, and query tools were then surveyed alongside storage and publication systems, together with case studies where these had been applied to assess their effectiveness and ease of use. Materials and toolkits for training were also reviewed to gain insight into their clarity and comprehensiveness. Finally, experimental modelling of real-world excavation data archives using various tools was undertaken as a cross-check. These experimental modelling exercises also provided critical insights into whether the data infrastructure and technologies of the CIDOC CRM were producing the kinds of knowledge desired by their users. The review presented here is preceded by a technology landscape synopsis that attempts to set our findings in the wider context of semantic modelling in cultural heritage.
Excavation research has been at the forefront of archaeological data interoperability activities. This is understandable as it remains the principal process for scientific data collection and interpretive reasoning in the archaeological domain. Data recording systems and methodologies that aimed to standardise the excavation process appeared even before the discipline turned towards digital options. In British archaeology, General Pitt Rivers and Flinders Petrie, followed by Mortimer Wheeler, are usually credited with the advocacy of more systematic documentation methods (Lucas 2000, 18-51), while similar developments gradually emerged in several national contexts. With the advent of Processualism, a new impetus was given to concrete documentation procedures, which included devices such as the Harris Matrix (Harris 1979), pro-forma recording sheets (see Chadwick 1997) and relevant field drawing guides (e.g. Bettess 1984) that gradually crystallised into context-based excavation manuals (e.g. Westman 1994). Very early in the adoption of digital methods within the discipline, approaches such as Gardin's logicist school tried to formalise the archaeological argumentation process (Gardin 1980), while similar attempts showcased the benefits of data linkages within large-scale documentation projects (Chenhall 1971). These were eventually followed by the development of data models (e.g. Andresen and Madsen 1992; Hadzilakos and Stoumbou 1996) and several digital documentation systems that tried to identify the main concepts and information flows within archaeological excavation projects, and attempted to provide database structures that could accommodate different fieldwork conceptualisations or excavation methodologies, e.g. ArchéoDATA (Arroyo-Bishop and Lantada Zarzosa 1995), IADB (Rains 1995), SYSAND (Agresti et al. 1996), IDEA (Madsen 1999) and ArchaeoInfo (Madsen 2003) or SIDGEIPA (Diez Castillo and Martinez Burgos 2001). Meanwhile, the increasing use of digital media in the archaeological documentation process raised the problems of digital data preservation and interoperability (Richards 1997).
Initial efforts were directed towards the integration and implementation of generic metadata standards, such as the Dublin Core (Wise and Miller 1997). However, a consensus was quickly reached that the heterogeneity and diverse implementation of archaeological information required more complex knowledge representation specifications to align the underlying conceptual schemas of existing information structures within a common framework, rather than simple resource metadata. The CIDOC CRM was perceived as having particularly strong potential for providing an explicit high-level event-based formal ontology (Doerr 2003), having already proven robust and flexible in the domain of museum documentation and other related cultural heritage subfields. Although, other proposals were put forward for the archaeological excavation domain (e.g. Kansa 2005; Zhang et al. 2002), the broad uptake of the CIDOC CRM by the cultural heritage sector and its accreditation as an ISO (International Organization for Standardization) standard in 2006 eventually triggered its further development and penetration into domain-specific implementations or facets that extended its usability, with significant impact across important elements of documentation in the archaeological and cultural heritage domains, illustrated by the creation of CRMdig, CRMsci, CRMinf, CRMarchaeo, CRMba and CRMgeo (Bruseker et al. 2017).
Despite these efforts to resolve conceptual and semantic problems, few examples of interoperable datasets exemplifying the utility of such work are published and accessible. The notorious diversity of archaeological methods, devices and data production practices is often cited as the leading cause for the continued lack of integration between datasets in terms of structure, granularity and terminology employed (see for example Attewell et al. 2004). This variability in how excavation fieldwork is envisaged, tooled and performed is reflected in the archaeological data archives we produce, which employ distinct conceptual descriptions at variable granularities, target diverse information outputs (a report or a data archive), can often be unfinished or open-ended, and may be linked to all sorts of digital data types, each with its own complicated production workflow.
The ARIADNE project as a European and, aspirationally, global project provided a useful proving ground on which to address these challenges. The ARIADNE project aimed to consolidate and aggregate into its infrastructure, the ARIADNE Content Cloud (AC), a large number of archaeological datasets of different kinds (ranging from excavation and survey data, to national monuments records, to heritage science outputs) (Aloia et al. 2017a; Niccolucci and Richards 2019; Richards 2023). The service supports searches based on spatial, temporal and thematic criteria for the retrieval of entire data collections with different levels of granularity, maintaining the conceptual links between different dataset levels (i.e., collection, find, trench, etc.) and enabling resource discovery (Aloia et al. 2017b). However, in contrast to contexts in which such efforts succeeded, such as the granular integration of coin datasets (Felicetti et al. 2015), the integration and retrieval of excavation data resources has remained limited and is mainly available in the ARIADNE portal at collection level and on the basis of subject keywords, rather than their item-level integration as individual objects. An example search using the terms 'neolithic ditch' illustrates the current modest level of integration and, implicitly, of semantic interoperability (Figure 1).
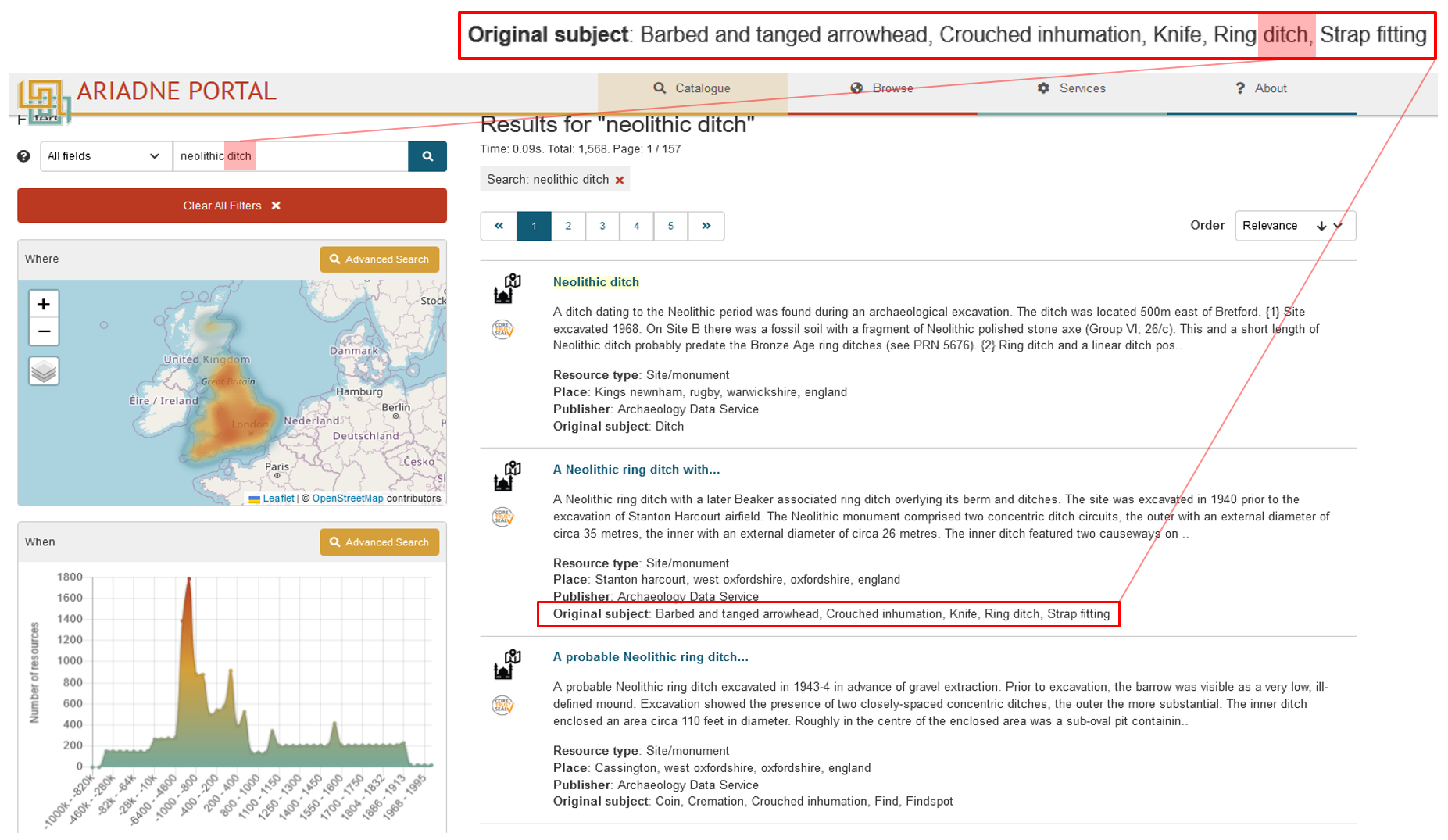
While the example from the ARIADNE portal shows a query run at the scale of a pan-European or global meta-aggregator of archaeological datasets, it also reflects the current situation in many national archaeological repositories, where excavation data archives are still usually integrated as project-level data collections, with severely restricted capabilities to accommodate interoperability at the sub-collection or item level (e.g. by enabling connections between individual finds from multiple excavation archives or aggregations of geospatial data documenting archaeological features). To achieve the goal of interoperable excavation datasets at those levels, beyond aligning different conceptual understandings of the excavation domain, we need to understand the root causes of persistent modelling problems, assess the fitness-for-purpose of available modelling and data mapping tools, and use this information to improve the practical toolkits available to support data modelling workflows.
As part of the ARIADNEplus project, the Archaeological Excavation Modelling Working Group was established to bring together what has largely been a fragmented community of scholars working on related research, review diverse strategies for excavation data mapping, consolidate data modelling expertise and provide a roadmap for further developments.
The group set out to investigate whether some of the problems in the alignment of conceptualisations of the excavation process could be solved through the creation of a dedicated archaeological excavation Application Profile (i.e. a model that reuses 'the elements of existing ontologies and models for the description of similar entities in the new research context, limiting the development of new elements only for the description of peculiar and typical aspects of the specific discipline', Richards et al. 2022, 10) or whether existing elements in the wider CIDOC CRM family of models suffice to enable sub-collection or item-level integration of excavation datasets. The theoretical complexities, practical barriers and the diversity of technological solutions involved in excavation data modelling made a straightforward assessment impractical, leading to the conclusion that a survey was necessary to map the overall landscape of excavation data modelling including existing efforts, tools, methods and, often not considered, skills requirements.
On 15 June 2022, the group organised a virtual workshop on semantic mapping of excavation data. The presenters explored semantic modelling and the use of CIDOC CRM, as well as the tools developed to assist researchers with mapping their data. Five case studies on semantic mapping of excavation data were also presented. A report from the workshop provides summaries of the presentations and the ensuing dialogue, as well as an overall discussion on the current landscape of excavation data mapping methods, tools and case-studies (Katsianis et al. 2022a). Video recordings of the presentations alongside an open-access version of the report have also been made available via the ARIADNEplus website through Zenodo, while a summary of the group's work (Katsianis et al. 2022b) has been included in the open deliverables of the project (Richards et al. 2022). Finally, a presentation at EAA2022 (Nenova et al. 2022) discussed some of our initial findings (see also Bruseker 2022) and provided the baseline for the present contribution.
The excavation data modelling landscape review, summarised here, revealed varied levels of technological maturity across different elements involved in archaeological excavation modelling. To structure the assessments, in finalising the review we assigned Technology Readiness Levels (TRLs) (EARTO 2014; EC 2014) to five key enabling technologies or research areas (Table 1). Many elements have been assessed as at technology readiness levels 4-6. This places many of the technologies in the middle to latter part of the 'innovation' phase, which includes technologies that are mature but not yet ready for robust operational deployment. However, level 7 technologies are also present, as in the case of AO-Cat, which according to Richards et al. (2022, 9) has reached a 'mature level of stability' and is ready for 'wider usage outside the boundaries of the ARIADNEplus' project (Table 1). Based on this assessment, we present the current implementation environment and set out a roadmap for future directions, highlighting areas where particular effort is needed and proposing mechanisms to increase the maturity of these technologies, while growing an early user community.
| Key enabling technologies/research areas | TRL | Description | Example |
|---|---|---|---|
| Conceptual models and semantic data structures | 7 | System prototype demonstration in operational environment | e.g. CIDOC CRM, AO-Cat, ARIADNEplus Knowledge base, GraphDB |
| Conceptual modelling patterns | 4 | Technology validated in a lab | e.g. Semantic Reference Data Models, Zellij Semantic Pattern Platform |
| Data mapping workflows and tools | 6 | Technology demonstrated in a relevant environment | e.g. Karma, Protégé-Ontop, SHACL, X3ML toolkit, Vocabulary Matching Tool, PeriodO |
| Learning technologies | 5 | Technology validated in a relevant environment | e.g. CIDOC CRM periodic table, OntoMatchGame |
| Semantic queries | 5 | Technology validated in a relevant environment | e.g. Openarcheo, Sparnatural |
In this section, the five key enabling technologies or research areas identified by the group as having potential to consolidate and coordinate ongoing work within the excavation data modelling community are discussed for their readiness levels through the retrospective consideration of their development, the presentation of diverse implementation examples and their integrative examination in the framework of ARIADNEplus.
Early efforts like CRM-EH (Cripps et al. 2004) tested the applicability of CIDOC CRM to model the archaeological excavation domain. Despite the overall suitability of the model, the identification of practical implementation issues and expressive gaps by the CIDOC CRM community (Ashley et al. 2011; May et al. 2011) motivated the proposal and development of a domain-specific extension for excavation research. Based on the documentation practices of several countries and in combination with CRM-EH, CRMarchaeo was developed to describe the specifics of the archaeological excavation process (Doerr et al. 2016a) with a focus on single-context excavation (Harris 1979). The model makes reference to concepts that were already provided by the CRMsci extension, itself developed to integrate 'metadata about scientific observation, measurements and processed data in descriptive and empirical sciences' (Doerr et al. 2012, 4).
CRMarchaeo's launch was followed by implementation examples that employed different excavation traditions (e.g. Masur et al. 2014), which revealed the necessity for additional concepts and led to further improvements (e.g. Hiebel et al. 2017). Further harmonisation efforts targeted other domains that interface with excavation practices (e.g. for building archaeology see Ronzino 2017 for spatio-temporal reasoning see Hiebel et al. 2014 for archaeological argumentation see Marlet et al. 2019b), while other examples included multiple concepts from several CIDOC CRM models (e.g. Hiebel et al. 2021; Christaki et al. 2017). The model has recently been upgraded to version 2.0 (Felicetti et al. 2023)
At its heart, the effort to integrate different standardisation initiatives carried out at a conceptual and technical level into a common information layer will depend upon a conspicuous and clear meta-representation of processes and objects in a consistent set of conceptual models. The conceit of the evolution of the main CIDOC CRM (CRMbase) into a series of extensions allowing domain-specific definitions is that their combination should potentially be more successful in capturing domain-specific meaning using targeted domain-focused extensions, while still adhering to the core ontological pattern. This strategy, while theoretically powerful, at a practical level has increased implementation difficulties as modellers have to navigate within an ever-expanding universe of concepts and properties and inheritances, while multiple implementation paths with complementary concepts mean that there is more than one way to express certain complex, real-world facts using the same, formal conceptual system. Because archaeological excavations are multi-level processes, often taking place across multiple fields, using diverse methodologies and tools, and producing a range of documentation media (see e.g. Jones 2002), modellers are regularly confronted with these difficulties when attempting to provide a coherent description.
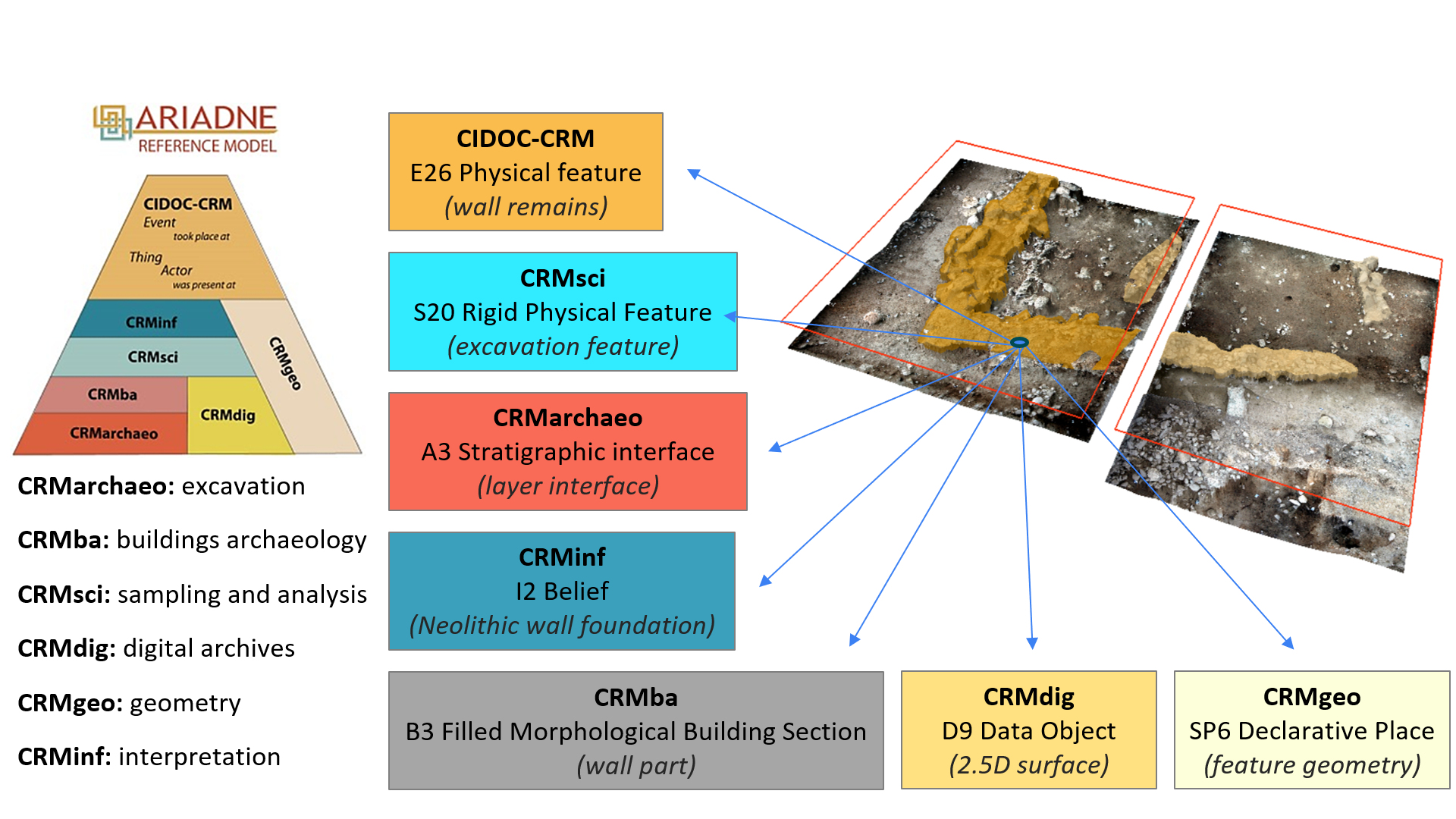
One key issue is that during excavation the meaning of real-world entities or their documentation proxies can be mapped to different model concepts, depending on the research context or stage. What may be identified as a feature (Ε26) during excavation may be referred to as a stratigraphic interface (Α3) that separates stratigraphic entities, as a rigid physical feature (S20) that can be examined for its properties, as a filled morphological building section (Β3) in architectural studies, as a belief (Ι2) to be a neolithic wall part in interpretative statements, as a digital data object (D9) that substitutes the original physical object in post-excavation research, and as a material entity that occupies a spatial location described through coordinate measurements (SP6). While such fine conceptual distinctions are the bread and butter of conceptual modelling, actually documenting, representing and relating them in practice is another matter. At a practical level, one needs to distinguish between different contexts or stages of the excavation process and establish common descriptions that facilitate a basic level of agreement (Figure 2).
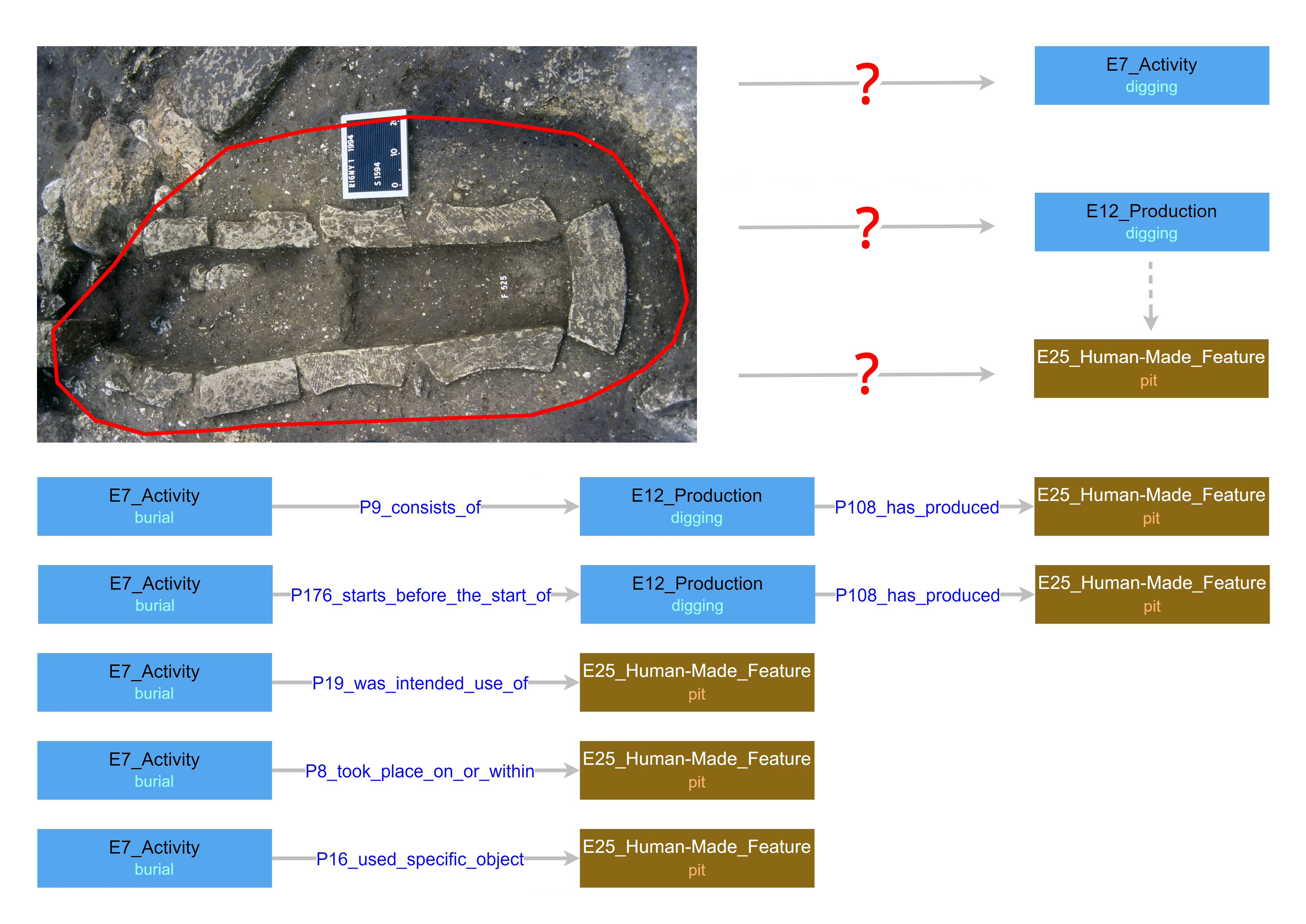
Another important issue is the multiplicity of potential paths for connecting entities and processes when modelling the same phenomenon. In the context of an excavation dataset, alternative semantic paths may be used to link entities and their underlying meanings, and these paths create strongly divergent results. This is important because the way an interpretation, for example that someone was buried intentionally, is linked with the archaeological evidence observed during excavation, reflects specific ideas we may want to highlight, such as past social activity, a specific action like digging, or the production of a burial place. Many possible routes can link the interpretation to the evidence. Some may be more direct or perhaps provide a better match with common archaeological data structures. While this directness or ease of modelling should be taken into consideration when choosing a path, it is also important to consider that the choice of route will affect the kinds of queries that can be easily run against the data (Figure 3).
Beyond these core conceptual difficulties, there is a practical barrier that regularly deters real-world implementation of CIDOC CRM models of excavation data. Changes to the CIDOC CRM concepts as a result of its evolution can require relatively frequent, labour-intensive updates that excavation projects do not have the resources to support. Although CIDOC CRM provides migration instructions for deprecated classes and properties (e.g. in CIDOC CRM v.7.1.1 - Bekiari et al. 2021 - the concept E38 Image was deprecated and replaced by the use of the more generic E36 Visual Item), the updates of descriptions required as a result may be more complicated, and resourcing this work will become more complicated over time, requiring curation provisions in the form of algorithmic techniques and tools for ensuring version control and backward compatibility (Tzitzikas et al. 2014). Even if the mechanisms are there to ensure the validity of semantic descriptions, the idea that a completed conceptual mapping may require updating or even radical re-engineering may act as a deterrent to the modelling community (for a relevant example see 4.3.4).
In light of these issues, the practical activity of testing the application of semantics from the entire CIDOC CRM ecosystem to archaeological excavation data, focused on assessing their conceptual and syntactic correctness, while mitigating the negative effects of too much diversity in the modelling choices deployed. The aim then became to understand how to consistently create, document and apply common conceptual modelling expressions to the same real-world situations. That said, exceptions to this, which identified gaps requiring new modelling, did come up with regards to the question of how to model the relationship of archaeological survey information to excavation data, as well as some nuances of chronological dating. In the first instance, the work of the Semafora project complements the existing official CRM extensions by proposing new CRM classes to represent the survey process and link it to excavation research (CRMsurv, see Nenova et al. 2023). In the second case, attempting to model the complexities of multiple temporalities (e.g. creation, deposition or recovery time of an artefact) that may also range between highly scientific and reliable (e.g. absolute dating) to more subjective and relative judgements (e.g. based on artefact typologies), led to the development of CRM classes and properties as a part of the CRMaaa model, an informal extension of the CIDOC CRM designed for application in the area of art and architectural historical research.
Finally, several application profiles, such as CRMhs (for encoding information derived from Heritage Science research), CRMtex (for the description of textual entities), the Mortuary Data AP (for modelling different types of burial data) or the aDNA AP (for capturing contextual information about the processing of respective samples) have been developed as part of the ARIADNEplus ontology implementation (Theodoridou 2022; Aspöck et al. 2023) and have potential to be linked with processes that form part of the archaeological excavation domain.
In considering the application of ontologies and semantics to archaeological datasets a gap exists between the possibilities enabled by such high-level representations and their practical implementation. In practice, archaeologists asked to model their information semantically face two challenges: understanding the ontology and its application and arriving at modelling compatible with that of others with whom they wish to share their data.
Application profiles are offered as a solution, consisting, in essence, of a subset of classes and properties from one or more ontologies, which are deemed appropriate and adequate to the modelling situation. OntoMe exemplifies an initiative to provide the tools to carry out this action (Beretta 2021). However, it does not enable a deep understanding of the ontology that its users are asked to apply, nor does it give specific instructions on how to string together the classes and properties in a consistent way to generate a consistent data representation.
Creating Semantic Reference Data Models (SRDMs) for early calls seealso Tudhope and Binding 2013) is another proposed approach, which seems particularly useful for describing the archaeological excavation domain. SRDMs provide a guide for how to implement a chosen ontology or ontologies within a certain context for a collection of typically documented items. A set of SRDMs covers a range of typical entities documented and their interrelations. Within the context of archaeological excavation this results in a meta analysis of the kind of things that show up in documentation and then creating a set of patterns for representing their typical attributes recorded, using the chosen ontology. It provides users with semantic patterns or recipes that can be reproduced. In doing so, explanations of what the model documents and how it is to be used can be described in the context of scholarly discourse rather than in the abstractions of an ontology. This approach can foster a less challenging familiarisation with semantic modelling processes for domain experts, increasing the possibilities for a greater number of compatible implementations. It can also provide critical studies of model definitions in an applied form and identify the problematic areas that require further development with respect to their ontological integrity or their compatibility with different archaeological excavation methods and interpretative procedures.
In our effort, we brought together data-mapping examples to explore similarities and differences, and compare their scope and meaning. The analysis of existing modelling examples and implementations has the potential to identify such modelling scenarios and provide a closer understanding of the evolution of the respective CIDOC CRM extensions (see for example similarities and differences in Cripps et al. 2004; Cripps and May 2010; Christaki et al. 2017; Giagkoudi et al. 2018). Such a strategy can obviously start from core or generic entities involved in the excavation process and subsequently be extended to cover more specific meanings. In carrying out this task, we also relied on existing work in the cultural heritage semantic data-modelling community, particularly borrowing from the patterns of the Linked.Art and SARI modelling work. Each of these communities have worked to develop fundamental patterns for the documentation of basic attributes of objects in the cultural heritage domain, from which we were able to produce suitable 'field' and 'collection' level modelling patterns, extending them and supporting the creation of a unique set of SRDMs for excavation data (Nenova 2022).
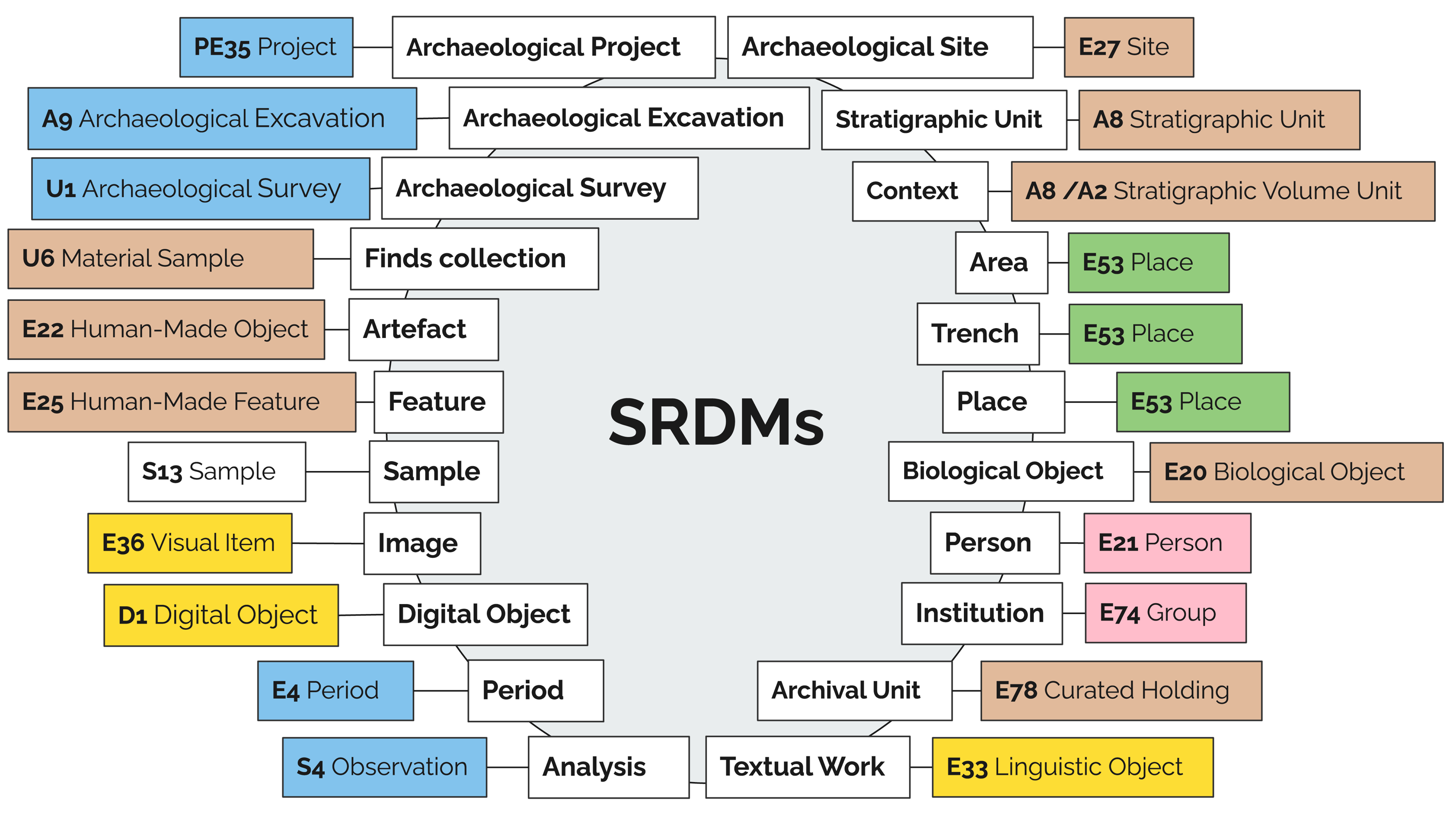
The common entities for all or at least most archaeological projects' records have to do with the process of excavation and the discoveries resulting from that process. These discoveries or the lack thereof further invoke the documentation of interpretative and analytical data and relationships. In total we have outlined 22 SRDMs covering important entities or notions of the excavation universe: archaeological project, archaeological excavation, archaeological survey, archaeological site, stratigraphic unit, context, area, trench, place, finds collection, artefact, feature, sample, image, digital object, biological object, person, institution, period, analysis, textual work, and archival unit. Although some of the SRDMs are still under development (e.g. analysis), we believe that the entire set allows the modelling of some of the most typical phenomena recorded in the course of archaeological work, providing reusable recipes for their documentation (Figure 4).
Archaeological Project (PE35) represents the overarching collection of activities serving a particular archaeological research goal. The core of the model records its timespan, participants and any descriptive information defining the purpose of the project or other relevant information. An archaeological project may include both excavations and surveys as well as different kinds of analyses and research. Since archaeological excavations and archaeological surveys have distinct natures in terms of methodology, techniques and field practices, they have been separated in two different SRDMs represented by two different CRM classes.
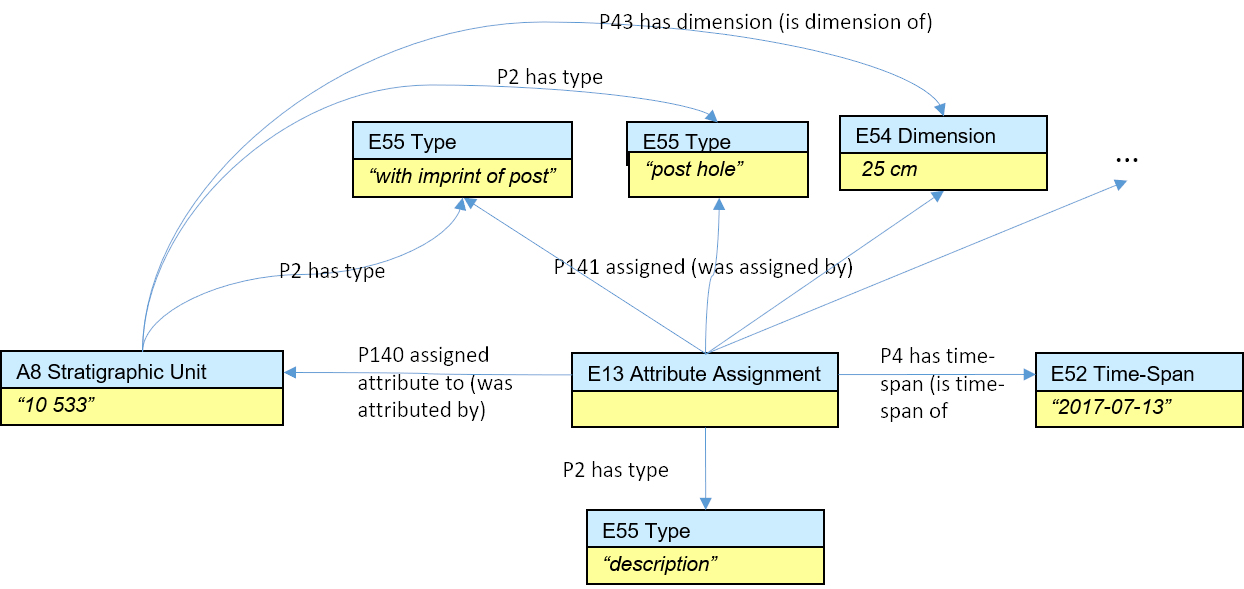
Stratigraphic Unit and Context SRDMs cover the main stratigraphic entities in archaeology, allowing us to determine and interpret synchronous events and their relationships with other events. Besides such relationships, these models allow information to be recorded about the dimensions, soil characteristics, inclusions, artefact associations, image, spatial information, as well as anything related to the process of excavation expressed by the CRM class of Archaeological Process Unit (A1) capturing the excavation activity. Under this node one can record the timespan, participants, techniques and tools used in the process and any other descriptive information that may relate.
Area, Trench and Place are three semi-overlapping concepts in the archaeological excavation documentation context. Both area and trench are modelled as place (E53) but serve somewhat different purposes depending on different project's excavation methodology. Such models capture spatial data, dimensions, related contexts and stratigraphic units. This SRDM consists of fields capturing data related to the description of a place as a geographic unit and associating various dimensions, geographic definitions and coordinate files. Each place or entity associated with a place (e.g. a feature) comes with the necessity of expressing spatial information, such as location coordinates and their coordinate system, which can be captured by a reusable pattern employing classes and properties from CRMgeo (Figure 5)
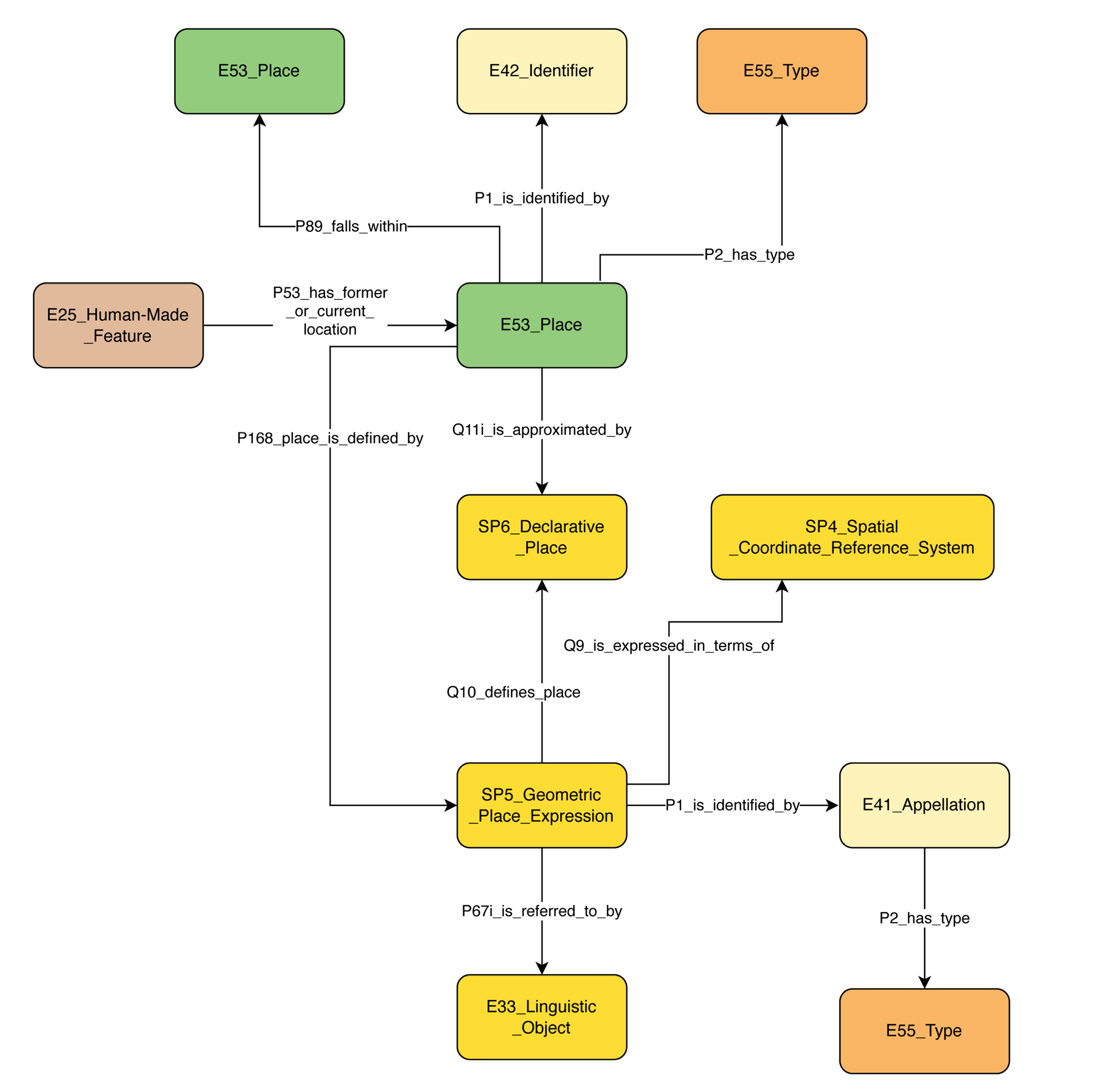
The Finds Collection model helps to document the cumulative collection of finds from a context or a survey unit. Its root node, U6 Material Sample, is borrowed from CRMsurv and functions as a subclass of S13 Sample and E18 Physical Thing. The finds collections are often referred to as 'bags' of finds and may contain human-made as well as any other physical or biological objects. Often these 'bags' are given an identifier in the field and later processed with a reference to this identifier along with other information related to the collection process. This model documents data around this collection process as well as definitions associated with various general types of objects collected, dimensions such as weight or count and other descriptive, spatial or documentation-related data.
The Artefact model (E22) handles information about any human-made object, inventoried separately or as a part of an associated group of objects. The artefacts may or may not be a part of the finds collections described above and may also require isolated spatial reference. Dimensions, typological descriptions, typological comparisons, chronological assignment as well as documentation reference are other types of data points included in this model. The contents and the associations of the Biological Object SRDM, created to document human and animal bones but including shell and other biological non-modified-by-humans objects, are similar. Information about human and animal bones discovered during the excavation are expressed as Biological Objects in a separate SRDM Bones (E20).
The Sample SRDM (S13) documents any portions of material extracted from a context or an object to be a subject of scientific analysis. Examples are radiocarbon, micromorphological, petrographic, etc. The model is set up to record data related to the sampling process as well as the physical nature of the sample and the type of analysis it is intended to serve. This model is closely related to the Analysis SRDM (E7), which requires further work to be able to apprehend all of the specifics of different analyses. The class Sample (S13) is employed to cover portions of an entity sampled to be analysed scientifically, involving analyses and techniques such as micromorphology, radiocarbon, OLS, etc. The model covers the process of sampling, the analysis involved and the interpretation of the results, the material nature of the sample with its dimensions and storage location, as well as any actors involved.
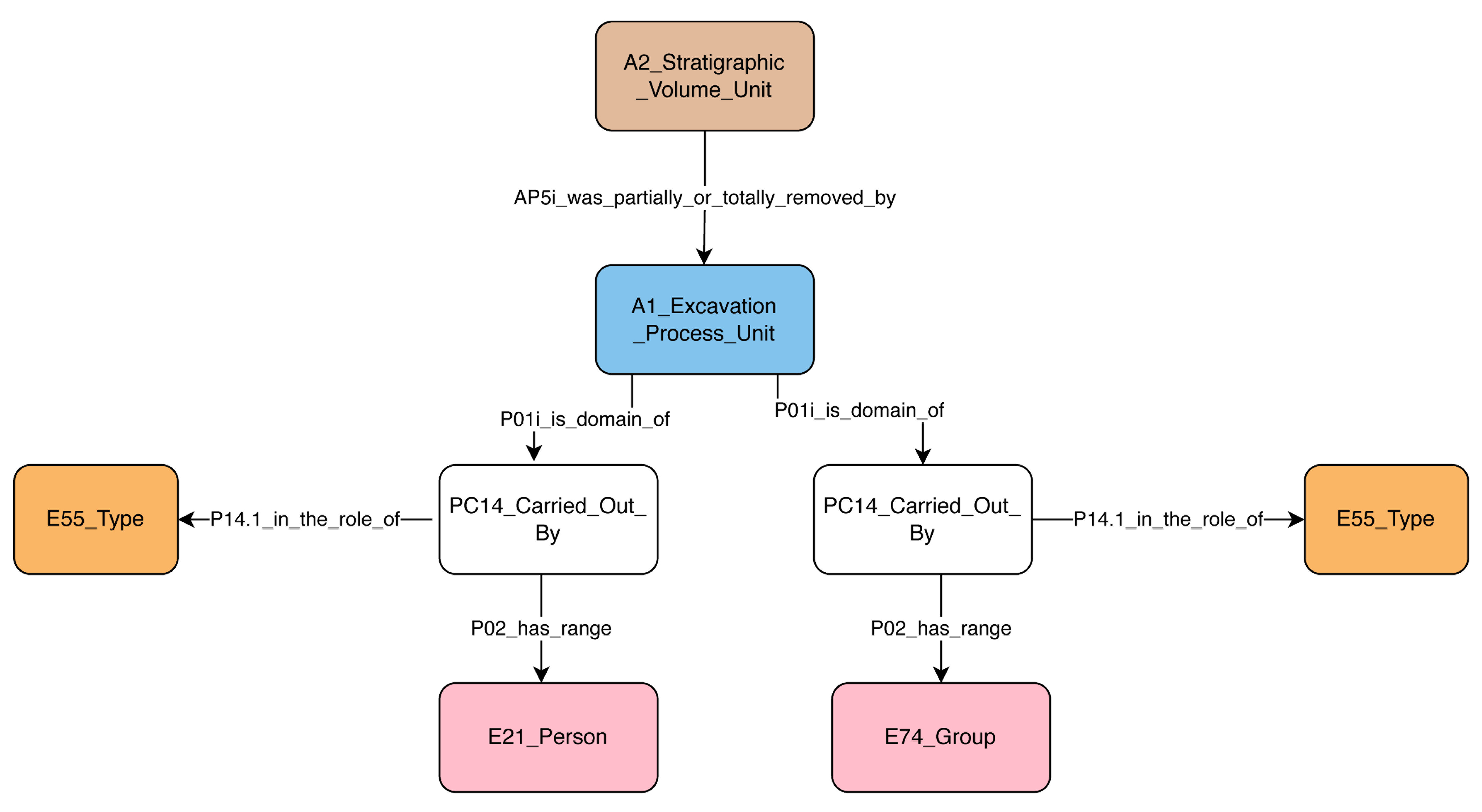
The Feature model (E25) captures any standing structures as human-made objects such as walls, floors, pits, hearths, etc. The relevant fields are similar to the artefact model without modelling the interpretative level of such structures at this point. Both Human-Made Feature (E25) and Human-Made Object (E22) classes stand to document the features/structures and artefacts respectively within Feature and Artefact SRDMs. The patterns cover data associated with their discovery, association with contexts and other features, levels of interpretation such as assigning types based on comparative studies, dating, current location, etc. Tasks are modelled to record activities such as drawing, photographic, sampling of the artefacts including types of tasks, assignees, timespans.
Most of these models have associated Image (E36) and/or Digital Object reference (D1), pointing at photographs, drawings, spatial files and any other available digital resources. Textual Work (E33) model stands for mostly bibliographic references or any 'notebook' data entries and reports. References to actual archives are recorded in an Archival Unit (E78) curated holding model.
Two models that exist as a reference in almost all of the other SRDMs are Person (E21) and Group (E74), which cover information about people and most commonly institutions involved in the projects and different activities associated with them. The SRDMs that refer to people and groups also contain fields where one can record in what capacity those actors were involved (Figure 6).
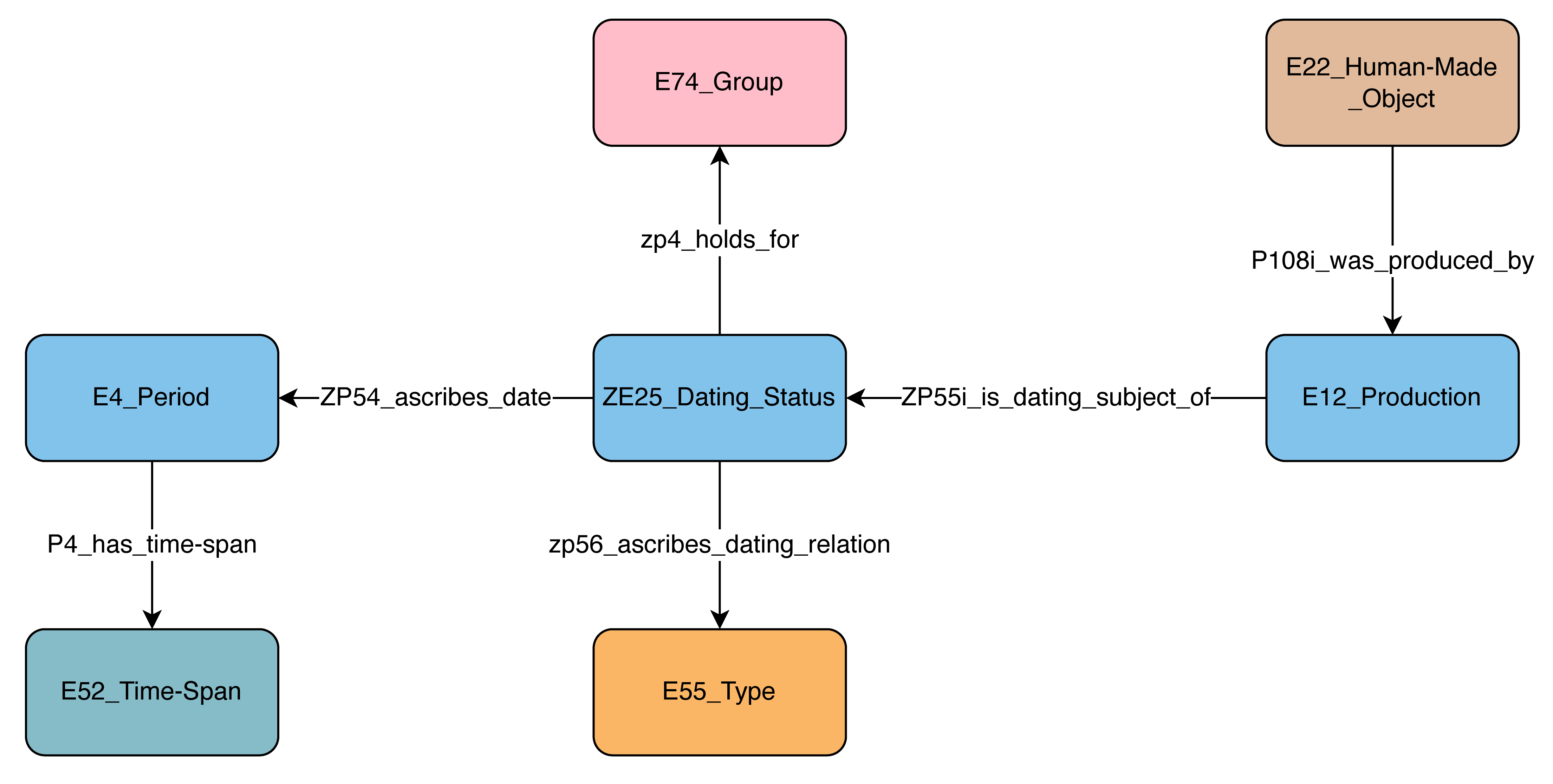
The Period SRDM (E4) replicates information about historical and archaeological periods known by certain names in different parts of the world. The period's timespan as commonly assigned by scholars, as well as its corresponding online reference uri, are also a part of the model (Figure 7).
The resulting work, derived from looking at different excavation data and excavation data modelling patterns, is a relatively comprehensive set of interlinking models that provide recipes for the implementation of consistent modelling patterns for common scenarios in the archaeological excavation data modelling context using CIDOC CRM and its extensions. The present state of the full documentation can be found in Katsianis et al. 2022b (annex B). This is a version 1 working draft that is targeted for further development: 1) to include concepts from unofficial CRM models such as CRMaaa or new/other APs, 2) to form a modular data description building process or a modelling cookbook, 3) to be linked to implementation examples and modelling guidelines, and 4) to provide a research avenue for the potential usability of Machine Learning (ML) procedures that could transform domain-specific semantic modelling into a marketplace for assisted data model creation or alignment (for an assessment of ML techniques for leveraging CIDOC CRM see Tzitzikas et al. 2022).
Counter-intuitively, the standardisation of the representation of archaeological excavation data through semantics leads not to a consolidation of set tools for the creation, representation and reproduction of archaeological data. Instead, it has opened the data to be taken up by a plethora of different software tools designed to handle different aspects of the data lifecycle. As a research area it is characterised by rapid development and little consolidation. What is interesting to observe in different efforts are the possible successful and unsuccessful combination of different tools to different ends.
In this section, we document several such methods in different use cases in order to illustrate some of the main strategies and tools presently used, and how they were put together into functional workflows for the generation and maintenance of semantic archaeological excavation data. Particularly, we have identified several different types of functionality that archaeological excavation semantic data is put towards: integration of completed research datasets, intra-organisational data homogenisation, the creation of archaeological excavation data ecosystems, the supply of meta repositories, and their applications in publishing. The use cases that follow illustrate the progress in these areas and how different tools are combined to create and make use of semantic archaeological excavation data.
An approach that manifests its usefulness for aligning finalised or closed datasets, attempts the direct creation of RDFs from spreadsheets or databases. An example of such a data-mapping pipeline employs the excavation data from the project Prehistoric Copper Production in the Eastern and Central Alps, which documents prehistoric mining activities in the eastern Alps of Austria following the documentation guidelines of the Austrian Federal Monuments Office (BDA – Bundesdenkmalamt).
An Open Research Data Pilot project led by the Archaeological Department of the University of Innsbruck, analysed the respective datasets and rearranged them into sets of spreadsheets or data tables that correspond with a combination of semantic standards, including the CRMbase with its extension CRMsci (modelling of physical things) and CRMarchaeo (modelling of archaeological documentation). Further concepts specific to Mining Archaeology research were mapped onto the DARIAH Back Bone Thesaurus, a metathesaurus, under which different vocabularies and terminologies in use in the domain of the Arts and Humanities can be aligned, while SKOS (Simple Knowledge Organization System) was used to organise specific vocabulary terms. Individual tables were then integrated within a PostgreSQL database that allowed further data structuring (e.g. URI addition). Afterwards, semantic tools, such as Karma or OntoText-Refine were used for RDF creation to be ingested into a triple store (Figure 8).
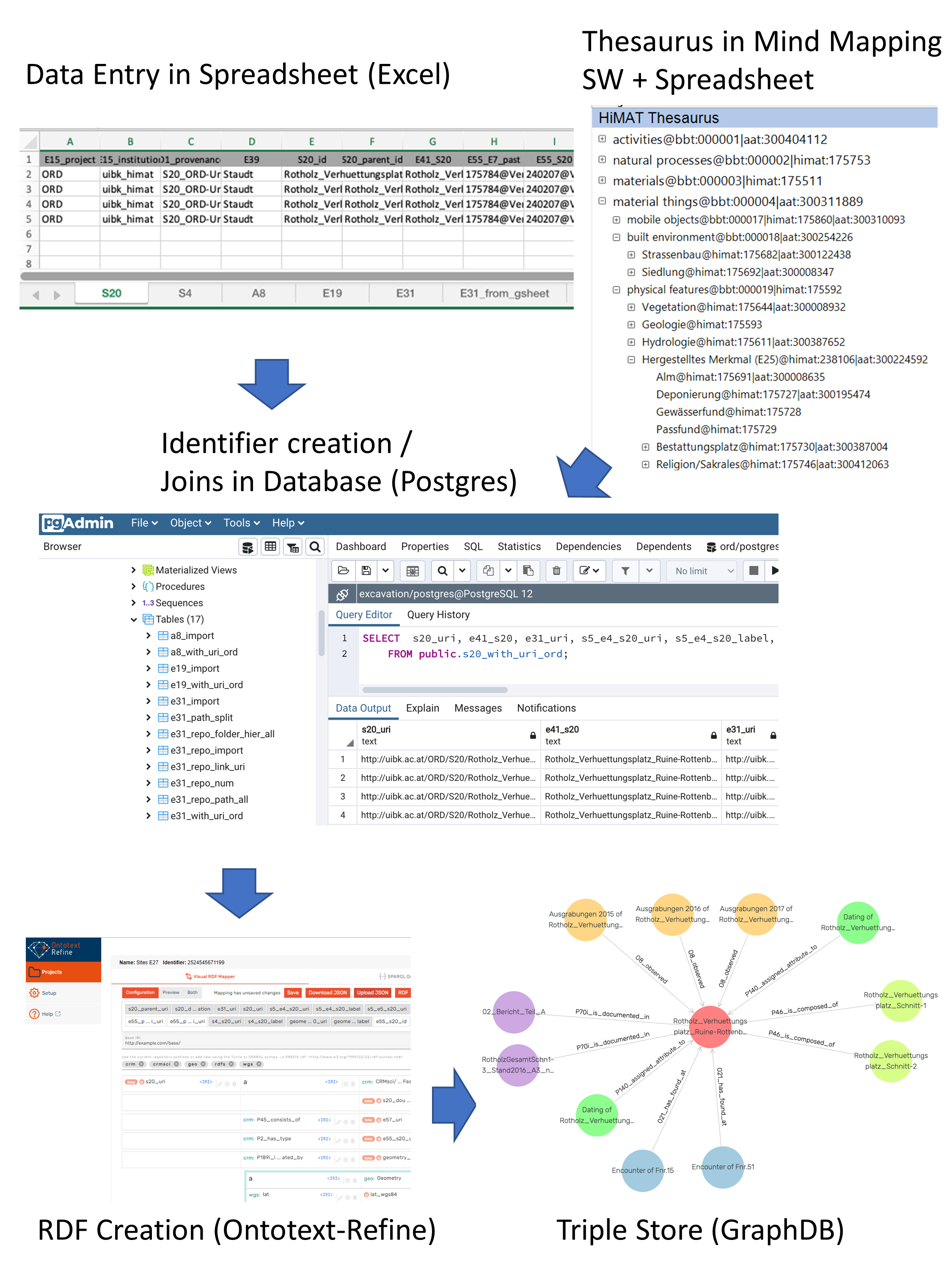
Ingestion onto the ARIADNE knowledge base required the inclusion of additional information in an 'ARIADNE Metadata' Excel spreadsheet, as well as the transformation of previously generated URI identifiers in ARIADNE-specific URIs for the ARIADNE repository within PostgreSQL. As a further step, concepts used in the research data were mapped onto Getty's Art and Architecture Thesaurus (AAT) and PeriodO following the data aggregation guidelines by ARIADNE. As a result, the bulk of information provided in the original network is also accessible via the ARIADNE catalogue (Hiebel 2022; Hiebel et al.2023). Mapping exercises that follow this approach can be pretty straightforward and have been incorporated into teaching resources in the respective university department. This approach can be very helpful for the transformation of individual legacy datasets into FAIR data structures. However, it involves intensive effort in data structuring and cleaning, requiring a balance between the mapping depth and the available resources. In many cases, where legacy datasets with different data structures are involved, such an approach may require decisions regarding the selection of the essential information worthy of being semantically aligned in each case.
In many cases, the adoption of digital documentation procedures may enforce a certain degree of conceptual conformity across an organisation or even entire archaeological sectors. The case of Norway is telling. Notwithstanding the standardisation of artefact databases since the 1990s, the introduction of digital documentation in excavations resulted in diverse solutions. In 2011, the Swedish INTRASIS was chosen as the default excavation documentation system across the archaeological sector. An INTRASIS database consists of two distinct parts: a metadata template and the actual data. The templates are object-orientated, enabling users to define class-subclass-attribute hierarchies and relationships between the (sub)classes. The flexibility and the ease of changing the templates on the fly may make data integration across individual databases challenging (e.g. Løwenborg et al. 2021).
In Norway the institutions responsible for archaeological excavations agreed to a common template, despite the possibility of adding restrictions to excavation documentation implementations. In the last 12 years this template has been revised on an annual basis. In addition, there have been ad hoc minor changes during excavation fieldwork, usually at the subclass and attribute levels. Consequently, individual metadata schemes may be similar but not identical, causing problems for data aggregation. The ADED (Archaeological Digital Excavation Documentation 2018-2021) project targeted the integration of hundreds of excavation datasets into a single searchable information system based on PostgreSQL/PostGIS, as well as data exporting provisions to a format conforming to the CIDOC CRM family of models, for compatibility with ARIADNEplus requirements. The analysis of the excavation databases in ADED contributed important insights that have been considered and used in the development of the current version 2.0 of CRMarchaeo.
This task was approached by mapping all individual templates to a single common template. First, an empty INTRASIS scheme with all tables extended with a column for data provenance, that is, the name of the individual INTRASIS database, was created. All individual databases were imported into this common database and analysed for their structural differences. In an object-orientated structure the 'class, subclass(es), attribute' hierarchy can also be transcribed into a set path from the root(s) to the attributes (leaves) (Figure 9).
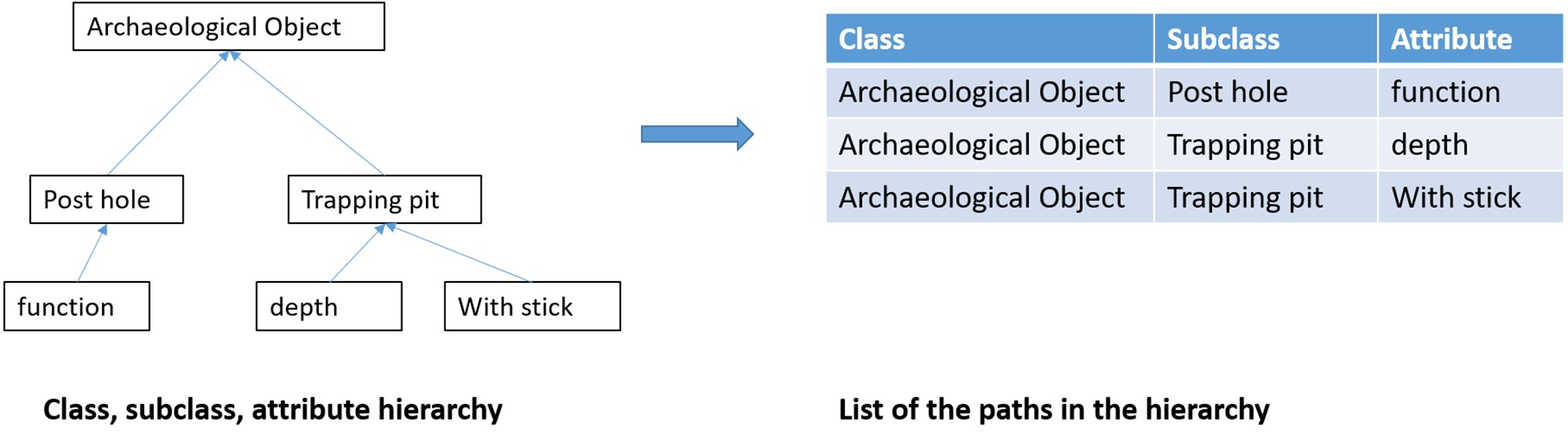
For a set of 597 INTRASIS datasets the path table consisted of 5100 lines. The normalisation process started with the classes, then the subclasses, their attributes and finally all relationships, requiring less than a month of manual processing. The results of this analysis contributed to an assessment of the degree of field usage that was used to inform the scientific board responsible for developing the national template. Afterwards, work proceeded with mapping the template(s) onto CIDOC CRM, including CRMinf, CRMsci and CRMarchaeo. INTRASIS classes were mapped to CRM classes while, surprisingly enough, almost all subclasses were mapped to types. Attributes were mapped to types or typed strings/values (Figure 10). The mapping of the relationships further revealed unexpected inconsistencies and singularities in the templates (Ore 2022).
The normalised path tables have been used in subsequent work involving data cleaning, term normalisation and alignment with reference thesauri (e.g. AAT or PeriodO). This workflow demonstrates the effort involved in aligning large numbers of similar datasets together, showcasing the benefits of following standardised denominations for database elements and controlled vocabularies, when implementing a data schema for archaeological excavation research.
The excavation data from the INTRASIS databases are published in the open ADED interface. In addition this interface gives access to the published excavation reports, photo documentation and artefacts. The interface for photos and artefacts builds on the unimus API, which is also accessible via the unimus portal. Links to the open version of the National Heritage and Environment Register, Askeladden, are also included. In this way, linking information at the site level is achieved, while further work should be directed towards facilitating linkages at the level of single structures within excavations.
In the framework of the MASA consortium of the French TGIR Huma-Num a workflow covering the archaeological excavation data life-cycle has been gradually developed and refined over the years using a set of operational open-source tools and infrastructures (Figure 11). These include a first step of dataset cleansing with OpenRefine and vocabulary normalisation with Opentheso, followed by ontology structuration and vocabulary alignment into interoperable data clusters that are subsequently mapped with Protégé-Ontop and validated with SHACL as an RDF TripleStore, to be finally implemented using GraphDB within OpenArchaeo, a federated semantic web platform. Using this generic backbone, an archaeological data ecosystem is formulated, linking data ingestion processes within a high-level interoperable data pool (Marlet 2022).
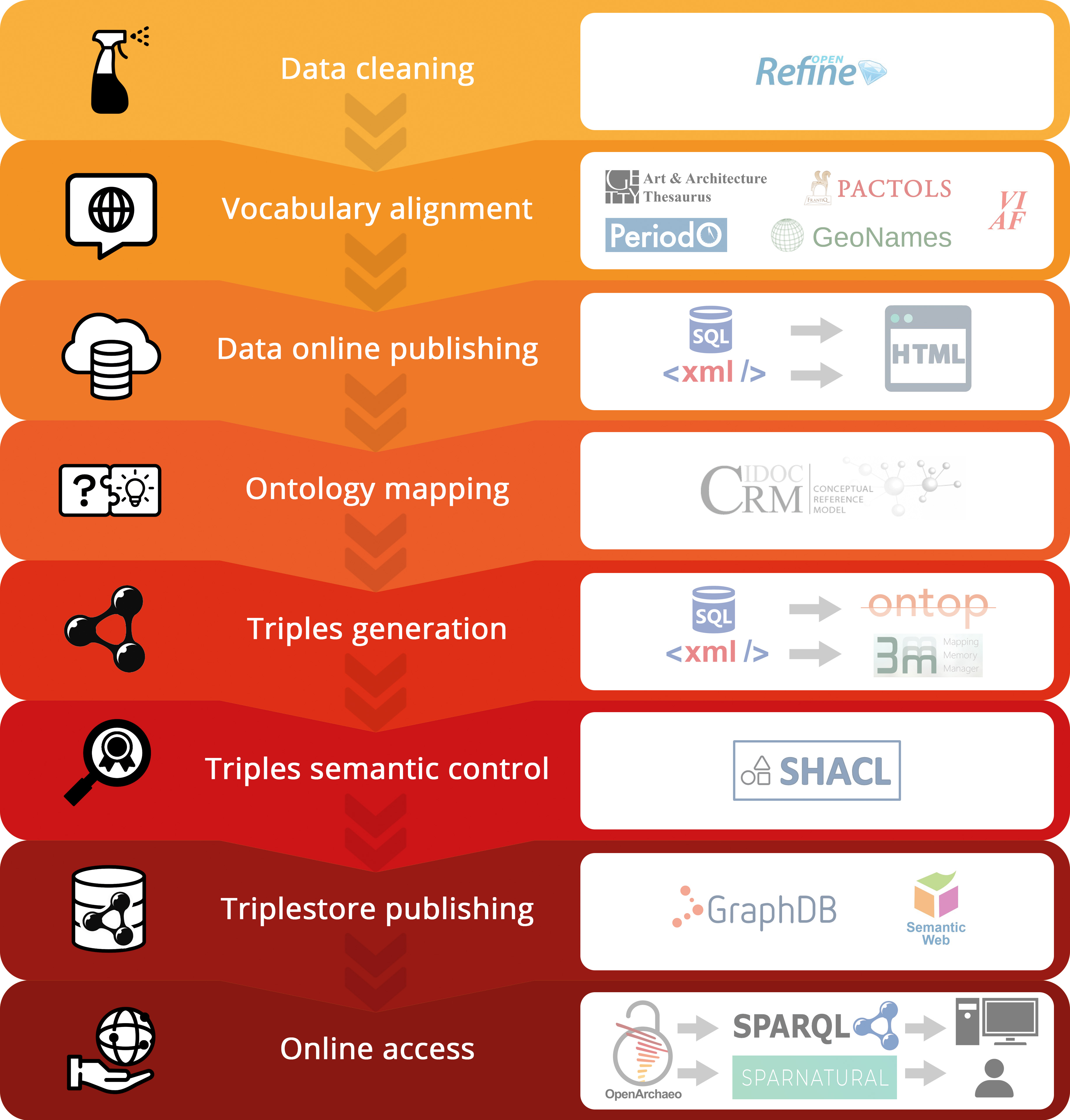
The conceptual glue is provided by a generic model that employs a selection of CRMbase, CRMsci, CRMarchaeo and CRMba entities, as well as relevant properties that are considered necessary and sufficient to represent the core of excavation data (such as archaeological site, artefact, documentation, etc.). Several gazetteers and standard vocabularies (PACTOLS, GeoNames, VIAF, PeriodO) are also employed to homogenise the terminology used across the various datasets. In this respect, the Openarcheo model provides an additional overarching conceptual overlay for heterogeneous datasets that identifies their main commonalities and allows their investigation.
The core functionalities of OpenArchaeo rely on Sparnatural, a Javascript-based system allowing the user to query an RDF graph with a graphic interface and without having to write directly in SPARQL. Instead, a visual query interface allows the user to query the RDF graphs without a deep knowledge of the CIDOC CRM ontology, facilitating the interpretation and translation of the OpenArchaeo generic model from Entities or Triplets into a sentence construction process. To allow for a more intuitive concept understanding, an 'editorial ontology' replaces the original denomination of the CIDOC CRM concepts and is supplemented by a system of icons for the main components of archaeological data. For example, E22_Man-Made_Object is communicated as «Artefact» in the interface with its own distinct icon. The result of a query provides a list of URIs that redirects to the source publication of the datasets (Marlet et al. 2019a; Hivert 2022 see also section 4.5 for an example).
In short, Openarcheo provides a data graph querying service in a simplified visual-based manner that makes use of a generic CIDOC CRM description that does not impose extensive semantic descriptions onto heterogeneous excavation datasets. In this respect, it provides one of the few existing examples in maintaining the original data structures, while allowing operational semantic interoperability.
As part of the data integration within the ARIADNEplus knowledge base, data mapping workflows for aligning completely different datasets employ the X3ML toolkit, which comprises a set of small, open-source software components for information integration. These include the X3ML Mapping Definition Language, the 3M Mapping Memory Manager, the X3ML Engine and the RDF Visualiser. The combined use of these tools facilitates a complete workflow for transforming XML exports of datasets/databases into CIDOC CRM compatible RDFs (Theodoridou and Kritsotakis 2022). This process can be combined with tools for achieving vocabulary homogenisation such as the Vocabulary Matching Tool (VMT) by the University of Wales (accessed also from within the ARIADNEplus VRE services to map concepts to Getty's AAT).
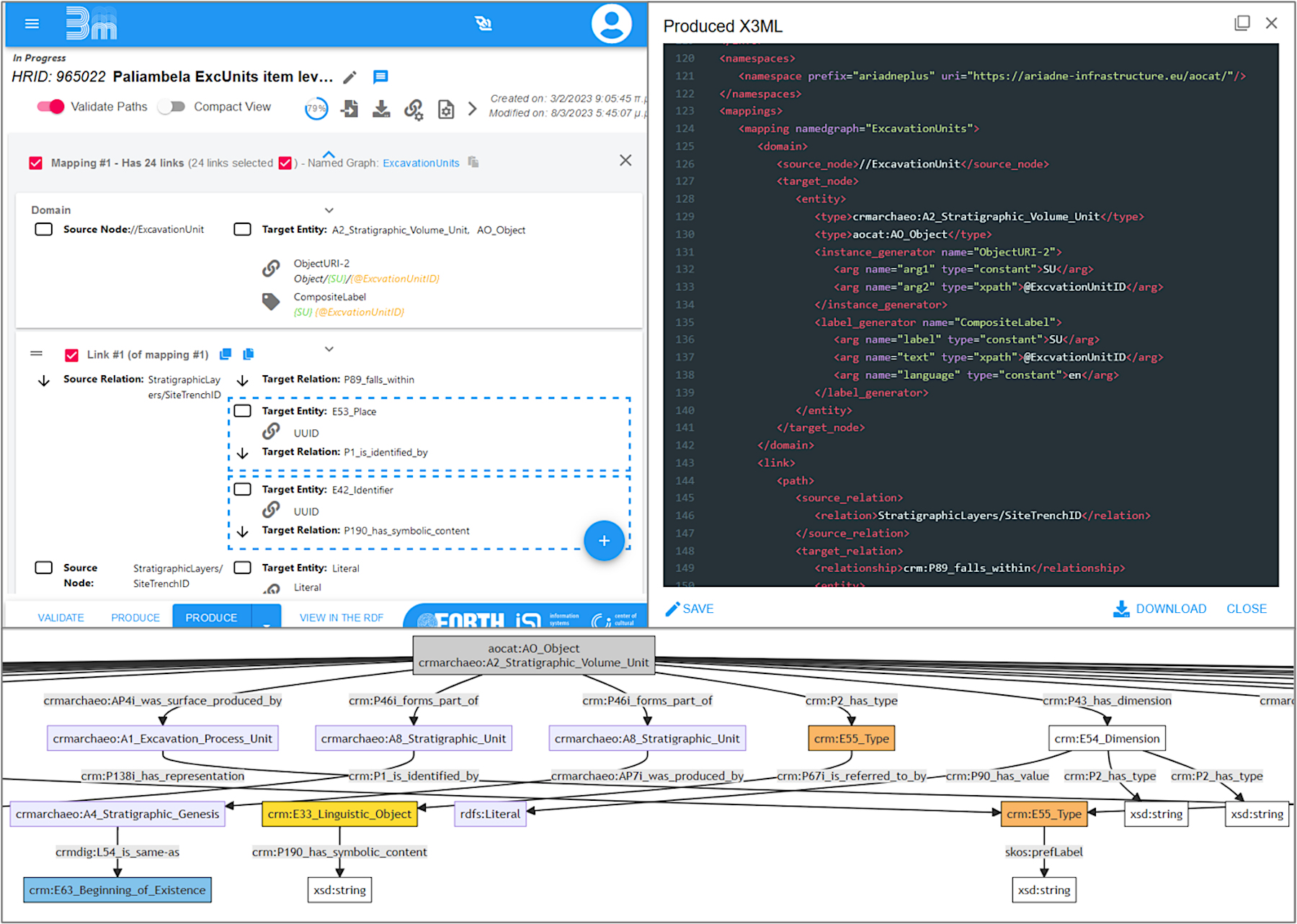
An example of such an approach was provided by the mapping of the Paliambela Kolindros excavation dataset, the product of one of the first 3D GIS documentation workflows that included conceptual modelling using CIDOC CRM v.4.3 (Crofts et al. 2008) to describe data components (Katsianis 2012; Katsianis et al. 2021). The preparation of a partial and incomplete 3D geospatial data archive for deposition almost a decade later has made numerous challenges apparent, some of which included the necessity to update the previous semantic description using concepts from AO-Cat and the entire family of CIDOC CRM models. The final data mapping tried to implement to a large degree proposed semantic patterns (see annex B in Katsianis et al. 2022b) and also experimented with multiple instantiation (Bekiari et al. 2021, 16), in order to connect concepts from different semantic sub-domains. Apart from the practical aspects of consolidating an excavation dataset, this process has led to many realisations concerning digitally assisted excavation documentation and reasoning (see Katsianis and Styliaras 2022).
In terms of tool usability the team followed the xml export of a flattened version of the database with the 'Excavation unit' as the core entity onto which all other information was attached. This strategy allowed the mitigation of problems in representing foreign keys. Apart from the sequential data mapping that prevents a holistic understanding of the mapping process, perhaps the biggest complexity encountered was the unavailability of the main modelling RDFs in the latest edition of the respective model definition versions on the CIDOC CRM site. The former issue can be mitigated by converting the resulting RDF into a visualised graph using the CRITERIA Live Demonstrator, while the latter was flagged to the maintainers of the CIDOC CRM site and steps towards the compatibility of model definitions with respective model RDFs have been undertaken (Figure 12).
Attempts to streamline the excavation documentation process all the way to web dissemination or open data accessibility, rarely include semantic provisions for the interoperability of the produced digital content (e.g. Nawaf et al. 2021). The Archaeological Interactive Report (AIR) was designed to provide an online system for fieldwork recording, 3D geometric documentation, data management, interactive visualisation and editorialisation of content, in an attempt to standardise digital-based archaeological reporting processes. The system is a hybrid solution that integrates the 3D visualisation and interaction components of 3DHOP into the Content Management System Omeka S. Using the excavation project of Västra Vång, Sweden, as a case study, researchers from DARKLab at Lund University and the National Institute of Art History in Paris (INHA) collaborated to provide a data structure for the system that covers different aspects of excavation documentation and data building, and is aligned with standard documentation procedures based on the widespread use of the INTRASIS system in Swedish Archaeology.
To ensure an easy future alignment with larger and international knowledge bases, such as ARIADNE, the data modelling included elements from the CRMbase and its extensions, CRMarchaeo, CRMdig, CRMSci to cover the basic entities of the model and their linkages. In addition, Dublin Core was employed to describe core metadata shared among the basic entities of the model, while Schema.org was employed to simplify the geographical allocations. Two further custom ontologies, air and tdhop, were developed to handle information about platform-specific entities and describe 3D visualisation parameters, respectively. Currently, controlled vocabularies are being aligned to common reference thesauri, such as the AAT, Geonames and Pleiades (Derudas et al. 2023; Derudas and Nurra 2022).
However, mapping the Västra Vång model to the CRM was challenging, especially because of the use of a non event-based data model consisting of numerous entities (e.g. in the case of an 'archaeological context', seven tables describe in detail the different context typology metadata). To provide archaeologists with a comprehensive tool for use in fieldwork documentation and also for report writing, the entire heterogeneous dataset had to be encompassed, enabling access to and linkages between all of its components. In this respect, to connect entities that could not directly be linked in CIDOC CRM, custom shortcut properties were defined to be eventually aligned through unpacking the short-cutted connections (see Figure 13).
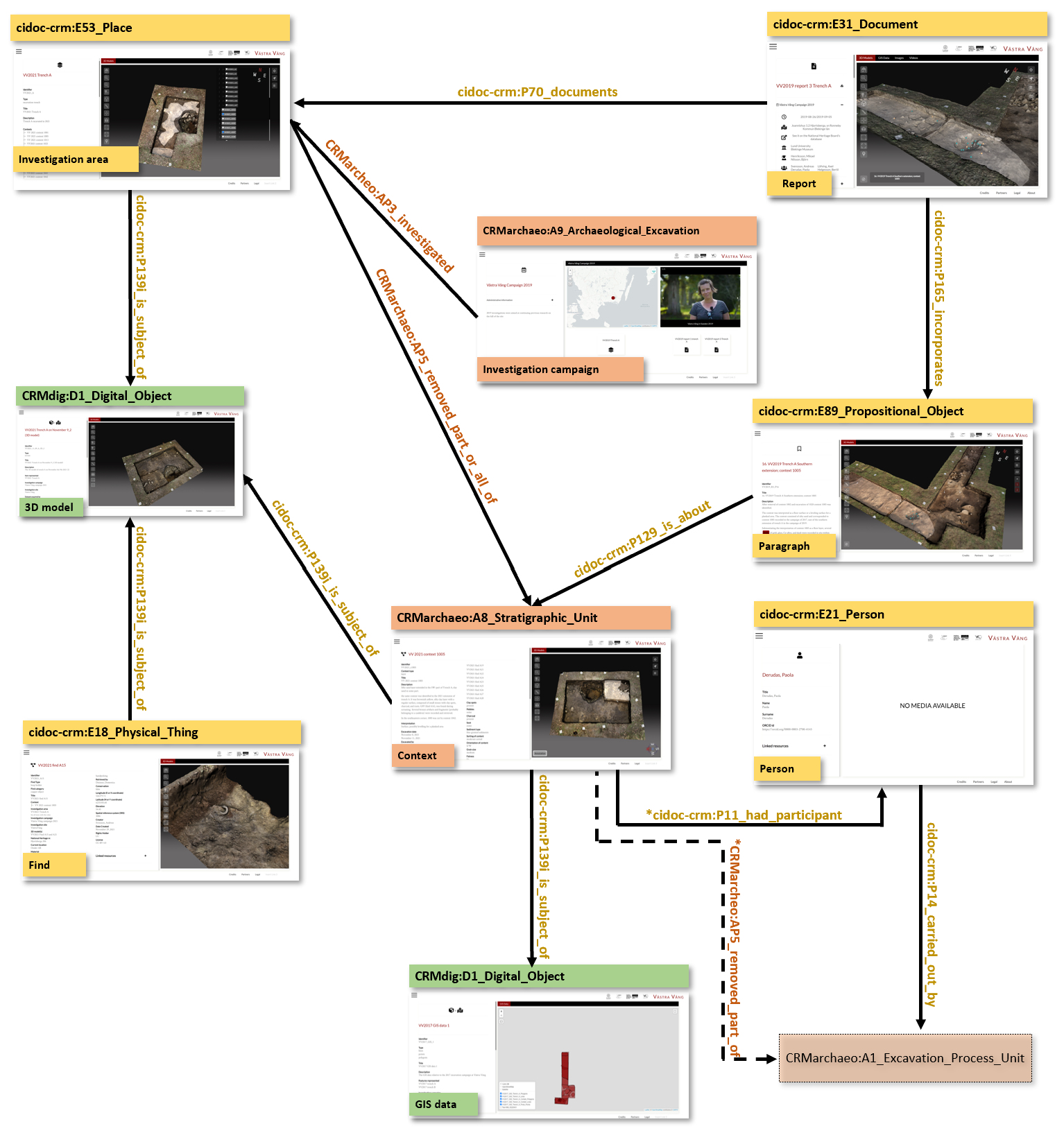
Although the model has not been implemented as an RDF Triplestore with a SPARQL endpoint, it showcases an extensive modelling depth that also takes into account issues of web page indexation as well as visualisation specific semantics (e.g. 3DHOP Scene), hence the need to include additional or custom-made reference ontologies. In many ways, it provides a useful example of the difficulties posed in application development and usability that stem from the fractalisation of data structures imposed by structured semantic descriptions (i.e. shortcutting long linkages) or the additional documentation requirements for different parameters of complex digital objects (related, for example, to the creation or the representation of GIS data and 3D models).
The cases presented demonstrate that the current ecosystem of data modelling and knowledge organisation tools is advanced, but also far from standardised. Depending on the structure and form of a given dataset (e.g. updatable content vs closed datasets) or the suite of digital tools that are employed in an implementation, some workflows may be more suitable than others. Work remains to be done in creating a clearer understanding and documentation of the kinds of use towards which semantic data is put and towards critically testing the tools and combination of tools that can be applied in different situations. For the more general uptake of such tooling, a more clear and generic elaboration of the workflows and documentation of the tools and methods that connect to them would be important areas of research. The purposeful further development of selected tools by the archaeological community and the explanation of the benefits or overlaps of specific tool sets with actual examples should also be pursued.
The appropriation and utility of semantic data, which depends on the user understanding the meaning of the data shown to them, ultimately depends on the adoption and apprehension of semantics by the intended target audience, in this case, field archaeologists. There is a fundamental challenge to meet here, given that the work of field archaeology and that of semantic data modelling are of highly different natures. To overcome this barrier, the provision of educational material, digital facilities and teaching opportunities for semantic modelling is key in order to enable an interested researcher to get up to speed. The production of such materials falls within the digital pedagogy, raising questions of digital literacy and its embeddedness in general archaeological curricula. The main goal here is to understand how to make the semantic strategy and its benefits accessible, reusable and ultimately attractive for reuse by its target audience in order to enable and further their archaeological research proper through the creation and integration of semantic datasets.
The main access point for those who want to approach the documentation and relevant material concerning the development of the CRM family of models, along with a history documenting the gradual solving of conceptual issues, can be found at the CIDOC CRM website. However, orienting oneself using the definition documents of each model and their documentation can be a difficult task for the uninitiated. The documentation is chiefly aimed at a semantic modelling audience, who already have a clear understanding of the concepts presented, rather than providing easy on-boarding documentation for those coming to CRM for the first time.
In order to address some of these shortcomings, several attempts have been made towards creating a more interactive engagement with the models for the learner and potential user during their familiarisation with the model concepts and properties. A very useful effort is outlined by the CIDOC CRM periodic table, available in GitHub, which presents an interactive point of access to the CIDOC CRM base facilitating learning through experimentation. Further relevant resources concerning tool, services, workflows and training materials for the entire data life cycle of archaeological data can also be discovered in the SSH Open Marketplace, a portal built by DARIAH to bring together, contextualise and make available a wide set of solutions and research practices as part of the Social Sciences and Humanities Open Cloud project (SSHOC).
Another very useful idea for increasing the awareness of entry-level practitioners is the CIDOC CRM Game created by Anaïs Guillem and George Bruseker, either as a tabletop or an online edition, OntoMatchGame. The former is available in different versions (e.g. preventive archaeology or excavation editions) allowing for the relevant material (board and cards) to be downloaded, printed and cut to facilitate in person seminars and class tuition. The player can deploy the cards widely and brainstorm about building a complete model. The latter is a digital edition that can be played online to explore semantic modelling concepts and linkages (Figure 14). Its design is orientated towards guiding the user to discover what an ontology is, how CIDOC CRM works and how to make mappings. In this respect, the two versions of the game complement each other. Both editions provide an entry point for potential domain experts who want to get a first playful interaction with the mechanics and benefits of semantic structures (Guillem et al. 2018; Marlet 2022).

The emphasis on the identification of excavation data modelling patterns by the present team (see Section 4.2) could provide a further step in semantic pedagogy through their compilation into the form of a cookbook for intermediate-level data modellers, targeting the gradual or eventual creation of an archaeological marketplace, including data modelling examples and workflows, complemented by structured tutorials, educational videos and targeted workshops, such as the formal training events in several tools and methodologies (including introduction to data mapping) offered periodically by the MASA consortium. Such intermediate and advanced training meetings can expand the range of modelling examples, bringing together diverse or complementary views of the excavation universe and informing both archaeological theory and data management methods.
Overall, there is still no systematic way for an archaeologist to develop a knowledge of the ontologies presented, but they must be learned through a variety of tools. The development of easier tools in order to understand the ontological standards is a good first step. The customisation of the material to address archaeological audiences is of prime importance in our context. The potential of moving forward on the basis of the SRDM patterns presented in Section 4.2 to create rich, complex teaching material is one way in which future research could look at addressing the problem of embedding this sort of digital literacy into archaeological practice.
The end goal of the adoption of semantic data strategies for archaeological information is to support archaeological research, the basis of which is the testing of hypotheses against empirical data. Thus, at the other end of the various efforts to develop models for representing archaeological excavation data, generating semantic datasets and learning how to create them, lies the ability to employ these datasets to respond to different kinds of archaeological queries. The task of thinking through what might form such competency questions, however, is not trivial. Moving from a local to a generic data structure with the possibilities of asking questions across excavation datasets entails thinking again about what we want to know from our data.
Would it be meaningful for example to query different excavations for Stratigraphic Units with a specific Munsell colour value? Probably not. The degree of meaningfulness of combining detailed data across different archaeological excavation datasets has been associated with the spatiotemporal extent of similarities identified in the archaeological record (Ore 2018), but there can be many more potential associations with variable usability. Certainly, some may be very useful from a research perspective (e.g. Roman coins from different excavations), while others may be more useful from the perspective of data management in the context of commercial archaeology or national/regional heritage agencies (e.g. cemeteries/tombs excavated between 1950-1970). However, one cannot exclude the possibility of associations that may prove meaningful after addressing the result of a particular query.
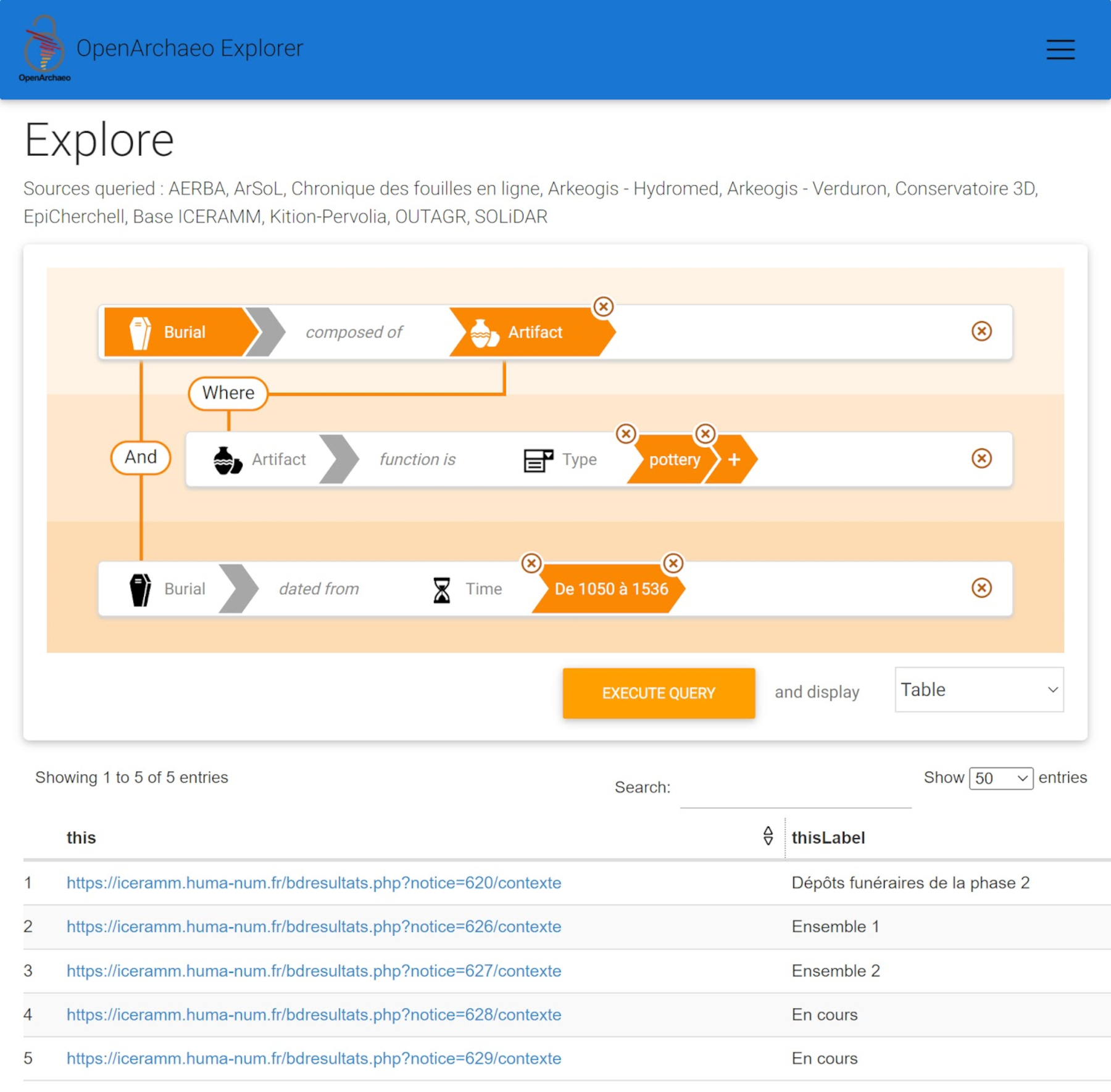
To understand the potential of acquiring information from aggregated excavation datasets we need to think of and try out questions that researchers and heritage professionals would formulate in order to retrieve existing reusable data. This exercise can outline the depth of the data description that is required to explore possible associations and, from a practical side, can reveal what each question involves in terms of the respective semantic syntax. Here we include an example of what a complex question that returns item-level entries would look like in terms of the syntax involved and showcase its practical implementation using the visual query interface of Openarchaeo (Figure 15).
Question: I want to find pottery that has been retrieved from burials dating to the Mediaeval period.
Response: all records of pottery artefacts of pottery type that are associated with Mediaeval burials
Semantic syntax: E25_Human_Made_Feature:
↘ P2_has_type → "burial"
↘ AP21_contains → E22_Human-Made_Object → P101_had_as_general_use → "pottery"
↘ P94i_was_created_by → E65_Creation → P4_has_time-span → E52_Time-Span ("Mediaeval"): ↘P82a_begin_of_the_begin →
E61_Time_Primitive ("1050-01-01")
↘P82b_end_of_the_end → E61_Time_Primitive ("1536-12-31")
This example also showcases the way chronological periods are aligned with start-end numerical dates to facilitate queries across timelines. In essence, chronological terms are aligned with time-spans that can be further regulated for their spatio-temporal overlap through facilities, such as PeriodO (see Section 2).
Similar semantic queries testing the response performance of complex queries across datasets at the item level using SPARQL have also been performed in ARIADNEplus using the integrated data from THANADOS, an online application of published archaeological and anthropological data of early medieval cemeteries in Austria (see Aspöck et al. 2023). This is rendered possible by accessing the ARIADNE knowledge base using the relevant GraphDB SPARQL endpoint functionality from the ARIADNEplus_Lab, developed to integrate different toolsets as accessible virtual services for setting up archaeological data processing, curation and retrieval workflows (Assante et al. 2022).
In any case, by posing questions and analysing their syntax we may succeed in identifying a minimum baseline for useful excavation data semantic descriptions. This exercise can help test the minimal and economical descriptions that can be standardised and reused in new data modelling pursuits such as those detailed in Sections 4.2 and 4.3. In addition, it can help test what an inclusive excavation domain description may mean in terms of basic concepts and linkages and how these can then relate to more exhaustive descriptions of the excavation domain or other related sub-domains. Finally, providing a set of predetermined question patterns that respond to typical archaeological questions and that can be used both within a specific dataset and across datasets would be a way of both making the semantic datasets generated more accessible and opening up new thinking on what it means to query across projects to reveal new, wider patterns, than those typically investigated based on single datasets.
It is clear from the discussion above that the overall field of semantic representation of archaeological excavation data is a lively and developing field, but we are clearly still some way from the seamless reusability of digital archaeological excavation datasets. The centrality of the excavation process as the most significant data generator of archaeological practice requires renewed attention in terms of its ontological significance and interfacing with sub-domain specific practices (like digital fieldwork documentation, laboratory studies and interpretative processes). The research undertaken by this group found that the present CIDOC CRM and official extensions alongside some proposed external extensions or application profiles are adequate for the raw task of semantic representation of data.
However, as shown here, the analytical work in the description of the excavation universe now needs to be complemented by synthetic attempts that can foster a more stable and user-friendly ecosystem of methods and tools for non-specialists to structure their data in meaningful and interoperable ways. To this end, we assessed conceptual models, modelling patterns, workflow and tools, learning and training and reusable queries to identify specific areas where further work in the standardisation of practice could lead to a more dynamic convergence of datasets and generate benefits for archaeological research.
Several concrete areas emerged as priorities for future research and standardisation. The ever-expanding universe of concepts, linkages and inheritances or possible deprecation of models may lead to increased difficulties in practical data modelling. Creating and sharing descriptions that cover how to generate typical data in different excavation stages or fields in an archaeologist-orientated way is an important development in semantic modelling patterns, which requires further testing and feedback from the community to assess its understandability and reusability. A more systematic analysis of the ways that data are interacted with and created in the semantic data context to identify the relations and dependencies between workflows and tools would be beneficial to many data users. This would enable consistent practices using particular tools to be built and reused by other practitioners. This does not imply a fixed set of tools or workflows, but rather improved guidance on the main tasks involved and which tools are adequate to each task. Good guidance would be an important step toward the standardisation of data integration practices. To this end, further work targeting the Synergy Reference Model (Doerr et al. 2016b) may bring the procedural requirements for data provision and aggregation into line.
Pedagogy around the use of semantic data in general is limited, and archaeology is particularly poorly provisioned. A patchwork of resources and tools offer a way to assemble an ad hoc knowledge of the semantic data process. Further work in this field could look to identify elements necessary to support a basic curriculum or curricula to support the archaeologist who wants to create or reuse semantic data. Many of the resources identified in this article could be more systematically deployed to that end. Finally, to provide convincing evidence that might persuade sceptics of semantic data, the elaboration of semantic data queries that both validate the representation and demonstrate how the integration of data opens new possibilities for research should be a priority. Again, further research is needed to achieve the necessary systematisation.
To return to the question posed at the beginning of this article, the jury is likely still out on the utility of the adoption of semantic data in archaeological excavation practice. This is not a result of the conceptual inadequacy of the programme or the proposed conceptual modelling constructs, which is the most technologically mature part of the ecosystem. Rather, the readiness for real-world use is held back by the ongoing fragmentation of efforts at integration of the wider conceptual and digital toolset into a real programme of action and study. Semantic technology and data proposals for archaeology find themselves at a moment of ferment, with many developments building off the platform provided by stable, standardised conceptual models for data representation. What is required now, as illustrated in the case studies presented here, is to consolidate this creative burgeoning toward a convergence of praxis in describing models, adhering to consistent workflows, generating engaging curricula to pass this knowledge into functional practice, and demonstrating the benefits and results through the creation, documentation and dissemination of suggestive queries.
We would like to acknowledge the editors for the invitation to participate in this special issue. This work was implemented within the framework of ARIANDEplus, a Horizon 2020 project funded by the European Commission under Grant Agreement n. 823914. The views and opinions expressed in this publication are the sole responsibility of the authors and do not necessarily reflect the views of the European Commission. An earlier version of this article was presented at the 28th EAA Annual Meeting in Budapest, Hungary 31 August 3 September 2022, in the session entitled 'FAIRly Front-loading the Archive: Moving beyond Findable, Accessible and Interoperable to Reuse of Archaeological Data'.
Internet Archaeology is an open access journal based in the Department of Archaeology, University of York. Except where otherwise noted, content from this work may be used under the terms of the Creative Commons Attribution 3.0 (CC BY) Unported licence, which permits unrestricted use, distribution, and reproduction in any medium, provided that attribution to the author(s), the title of the work, the Internet Archaeology journal and the relevant URL/DOI are given.
Terms and Conditions | Legal Statements | Privacy Policy | Cookies Policy | Citing Internet Archaeology
Internet Archaeology content is preserved for the long term with the Archaeology Data Service (ROR). Help sustain and support open access publication by donating to our Open Access Archaeology Fund.
 Home
Home